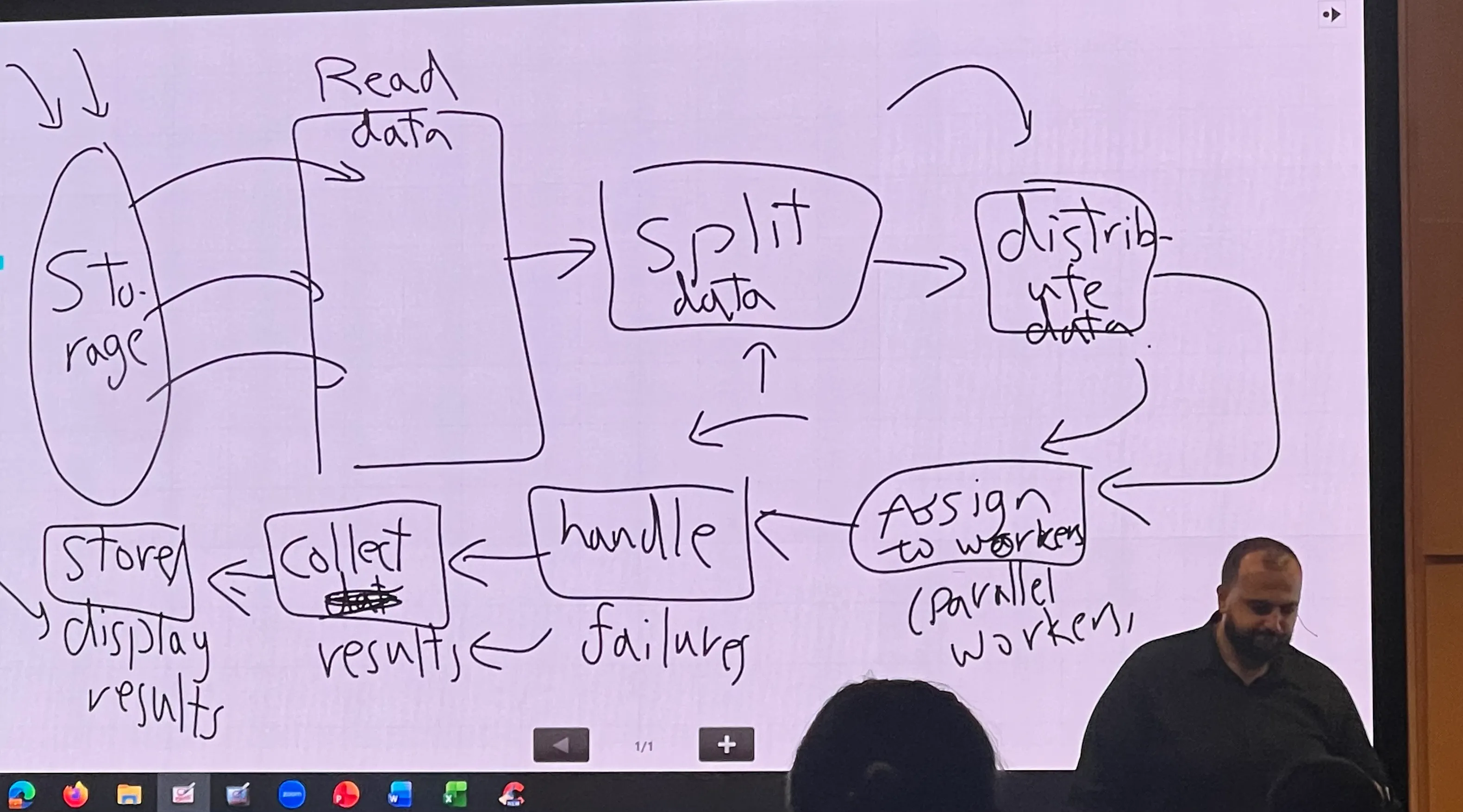
How traditional distributed system dealing with data:
It is too complicated to build a distributed system from scratch
Now MapReduce comes in and abbreviates this process by taking care of most parts, except for collecting results, and processing the data before handling failures.
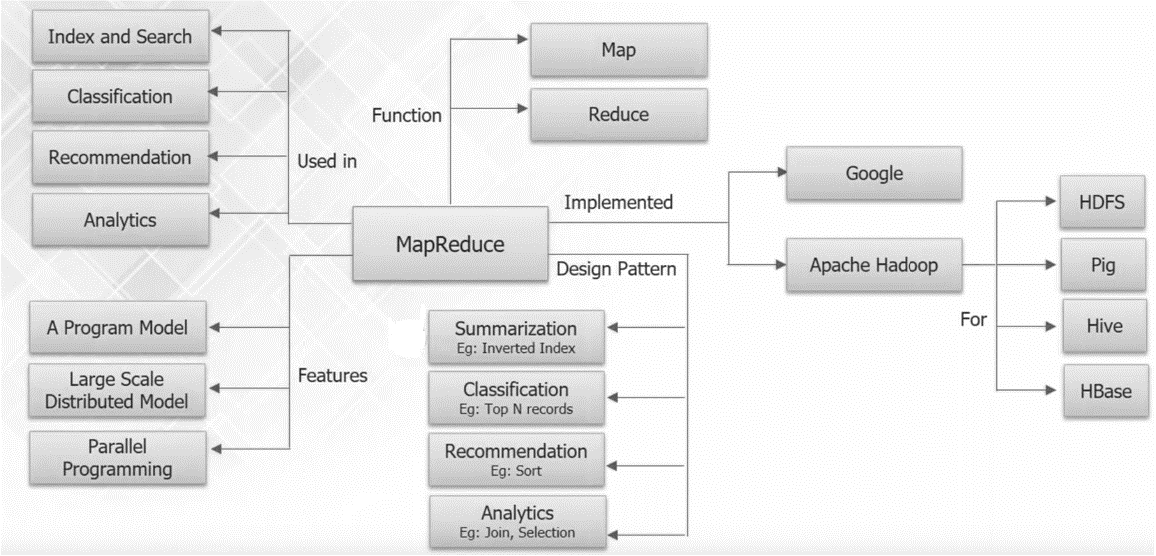
MapReduce
Definition
A programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a Hadoop cluster.
It abstracts the problem from disk reads and writes, transforming it into a computation over sets for keys and values
It works as a batch query processor that can run an ad hoc query against your whole data set and get result in a reasonable time. Not real time processing.
Scalability and Parallelism
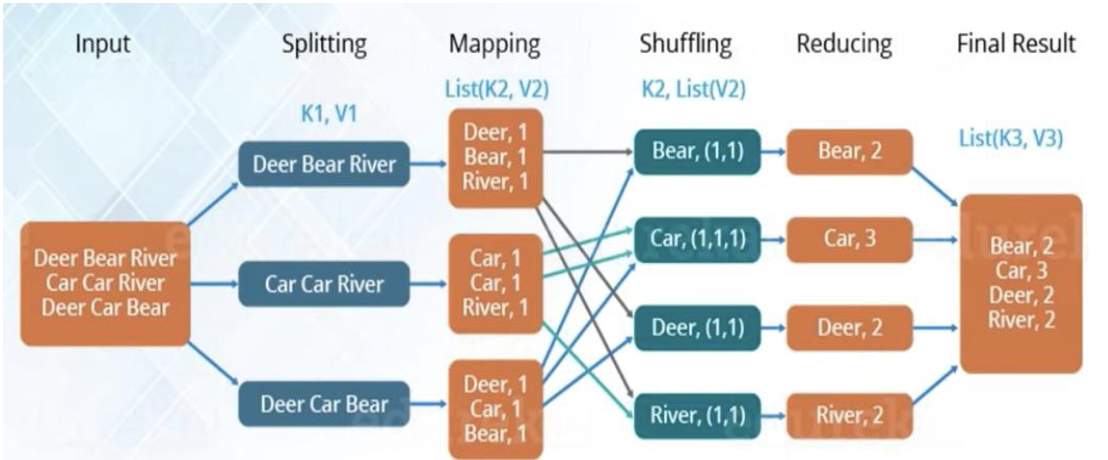
Word Count Example:
Input: a large collection of documents
Output: a list of (word, count) pairs
First phase:
Define WordCount as Multiset;
For Each Document in DocumentSubset {
T = tokenize(document);
For Each Token in T {
WordCount[token]++;
}
}
SendToSecondPhase(wordCount);
Second phase:
Define WordCount as Multiset;
For Each Document in DocumentSubset {
T = tokenize(document);
For Each Token in T {
WordCount[token]++;
} }
SendToSecondPhase(wordCount);
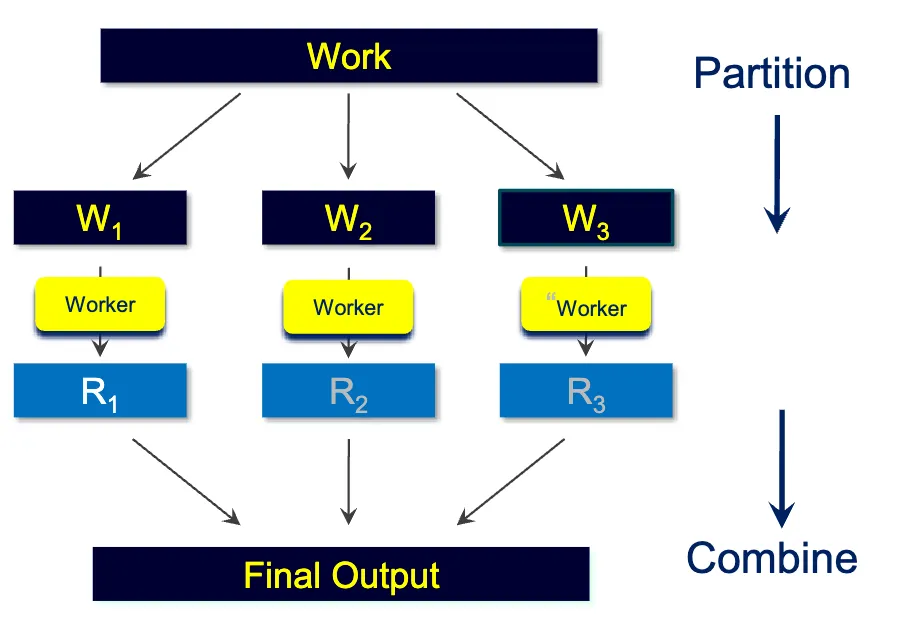
We want to execute both phases in a distributed manner on a cluster of machines that can run independently.
So we do Divide and Conquer:
Challenges:
How do we assign work units to workers?
What if we have more work units than workers?
What if workers need to share partial results?
How do we aggregate partial results?
How do we know all the workers have finished?
What if workers fail?
Distributed system developer mindset:
The order in which workers run may be unknown
The order in which workers interrupt each other may be unknown
The order in which workers access shared data may be unknown
Details in MapReduce
A data intensive programming model as a framework for key-based operations
Underlying runtime system (YARN + HDFS)
Automatically parallelizes the computation across large-scale clusters of machines
Handles machine failures, communications and performance issues.
What are Map and Reduce functions:
Map:
Iterate over a large number of records
Extract something of interest from each record
Shuffle: Shuffle and sort intermediate results - Taken care by Hadoop!
Reduce:
Aggregate all intermediate results for a given key
Produce final output records
So Word Count in Hadoop MapReduce (similar to Kafka broker):
In input split, the key value is the byte offset.
In mapping, we control the hash function such that we make sure same words get the same hash values and words of the same hash value will be sent to the same machine.
Job Components
Definition: A MapReduce Job is a unit of work that the user wants to be performed. The job consists of:
The Hadoopkeeps the source code in the local cluster, but data in HDFS. Because when we are dealing with Big data, we keep the data where they are and we move the source codes, processes to the place where the data are stored. This is called Data localization.
Data Flow - Map
The Input data are divided into fixed-size pieces called splits
One map task is created for each split
The map function is run on each split
Configuration information indicates where the input and the output are stored.
The maximum number of Mappers you can have in an application is equal to the number of your input data splits, because each input split is processed by exactly one Mapper.
From Map to Reduce
Select a number R of reduce tasks.
Divide the intermediate keys into R groups,
Map tasks use efficient hashing function to group keys that should be sent to the same reducer.
Each map task transfers each group of keys to one of the R reducer’s container
Once all mapper task results are transferred to the reducer, the reducer merges the results and computes the final output
All values with the same key are reduced together. The reducer then writes the output to HDFS
Decomposing a Problem
Map task focuses on:
Extracting the key and temperature from each line in each file
Emitting intermediate key-value pairs
Hadoop will accumulate all the values for a given key and pass them to a specific Reducer
Reducer task focuses on:
Aggregating all the values for a given key
Find the maximum temperature for a given year in the NCDC Example
Emitting final key-value pairs. Writing the output to HDFS
Read Output
Each reducer writes the output in a separate file on HDFS.
Merge the output files and copy them to your local cluster:
A mini-reducer that performs in-memory local aggregation of the intermediate outputs after the map phase (inside the memory of the Map tasks) and before the shuffle phase.
Reduces the amount of intermediate data (key/value pair -> network traffic) transferred from the Mapper to the Reducer
But if there are too many hetero elements, it’s no longer efficient which means it is almost like doing another reduce task on the map node.
Partitioner(k’(key), num_of_partitions=num_of_reducer) -> partition for k'
Controls the partitioning of the intermediate map output keys. Splits the map output records with the same key.
Divides up key space for parallel reduce operations
Executes on each machine that performs a map task as a local partitioning.
Default partitioner: hash function that computes the hash value of the key and assigns it to a reducer based on the number of reducers.
e.g., partition = hash(key) mod num_of_reducers
Custom partitioner: user-defined function that controls how the keys are distributed to the reducers.
Customization Parameters
Control number of reducers in your app: -numReduceTasks N
Partitioners can help you create compound keys: -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
Comparator specifies a custom method to sorting keys at the shuffle and sort stage. Example:
yarn jar /opt/hadoop/hadoop-streaming.jar \
-D mapreduce.job.output.key.comparator.class=\ <!-- Specify a custom key comparator class -->
org.apache.hadoop.mapred.lib.partition.KeyFieldBasedComparator \
<!-- treat "." as the delimiter between key fields. -->
-D mapreduce.map.output.key.field.separator=. \ <!-- -k2,2: sort by field 2 only; n: numeric sort; r: reverse order(descending) -->
<!-- Sort keys by their second field numerically in descending order. -->
-D mapreduce.partition.keycomparator.options=-k2,2nr \