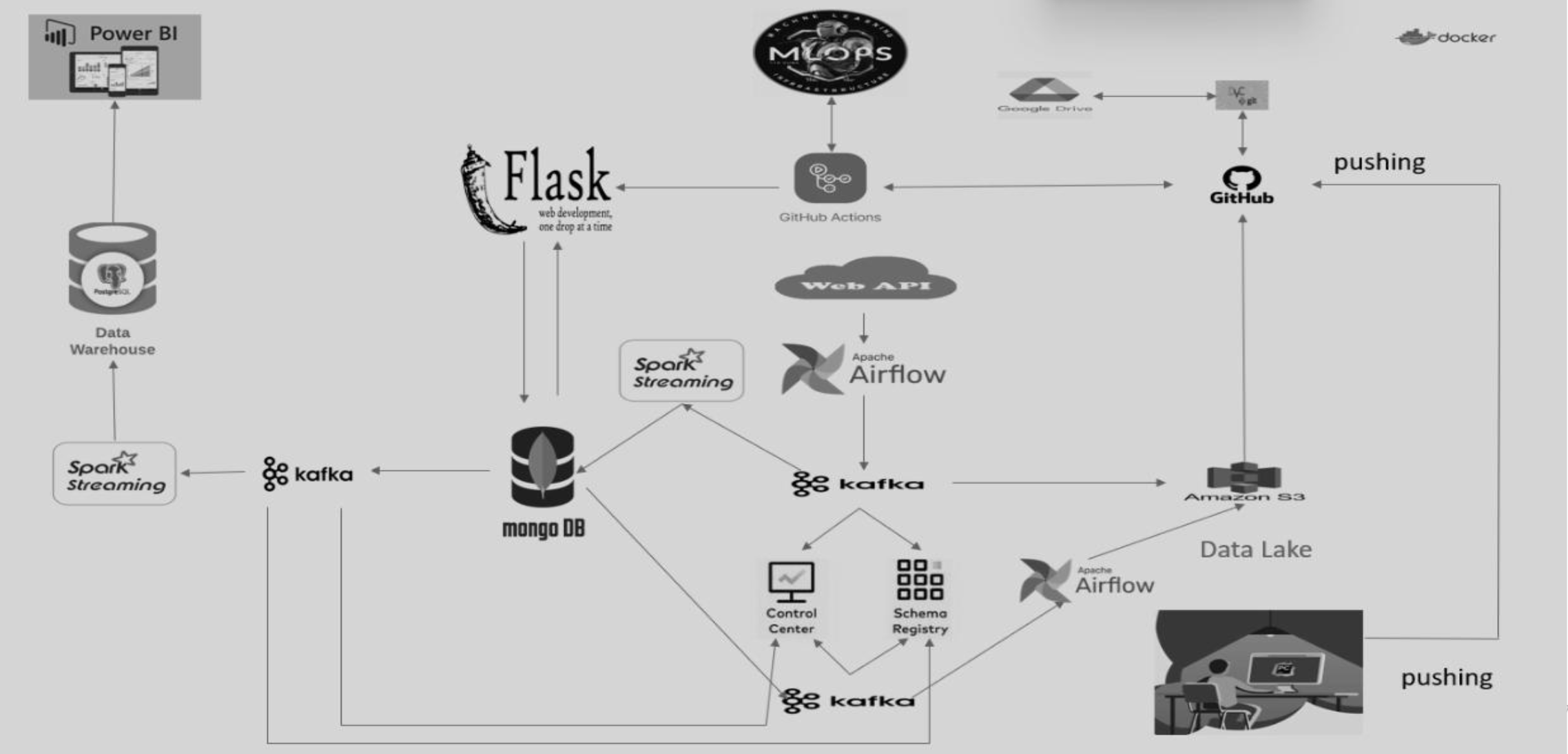
Problem of Request-Response Architecture: Kubernetes offers the ability to (de)scale your applications to respond to user requests in a meaningful amount of time.
Process of request-response architecture:
user sends a request to your application
k8s master reroutes the request to an available pod,
not enough pods
HPA
Still not enough
VPA
more requests
Connection timeout
Interruption
If the number of user requests continue to increase beyond your K8s cluster resources, 1) your k8s master won’t have enough memory or processing power to reroute the incoming traffic, or 2) there are no available pods to process requests, and no more pods can be created.
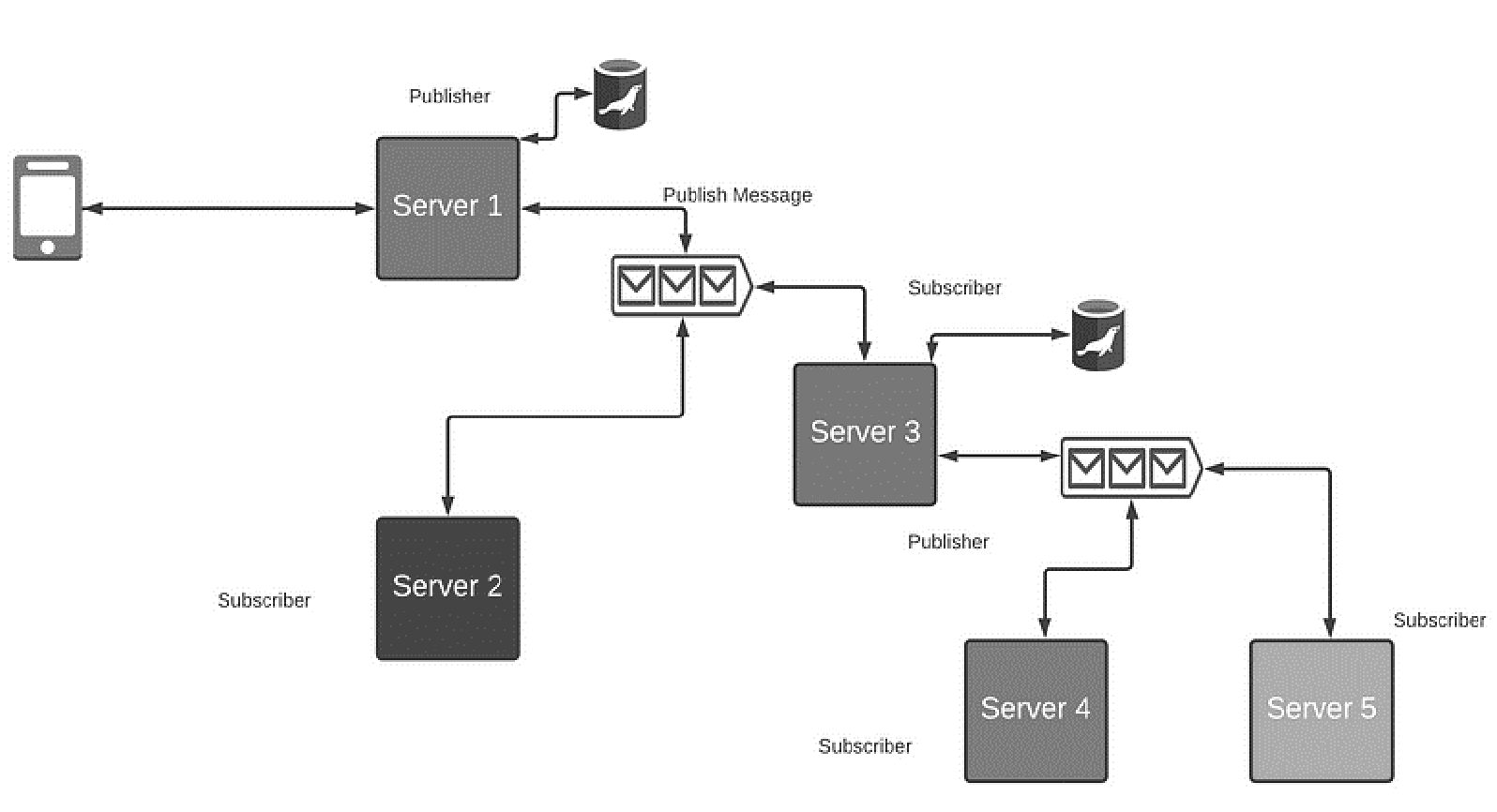
Solution: message queues: Kafka acts as a buffer between user requests and your application to avoid message drop & timeout problems. It is a scalable message queue with publish-subscribe software support that offers distributedstreaming processing.
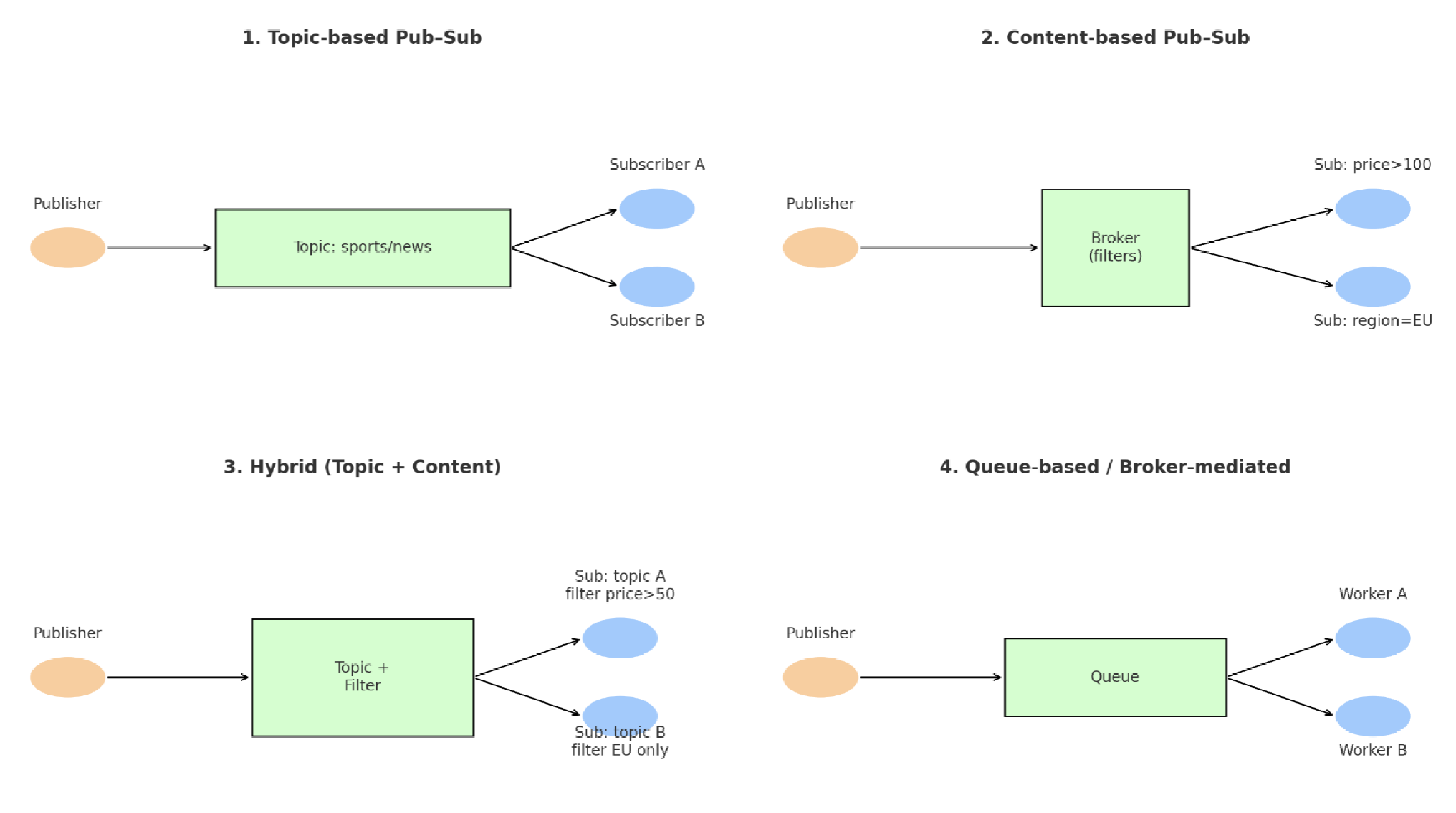
Digression 1: Publish-Subscribe Model
Model 1 → Kafka: Sub A and B get the same message from the topic they subscribed to. They get the full copy by default. (topic-based pub-sub model)
Model 4 → Active MQ: Load balancing, traffic distribution, such that if messages A and B are sent, then Worker A only gets A, worker B only gets B. (queue-based/broker-mediated model)
Model 2 → JMS, AWS Event Bridge: Subscribers find the condition / set the filters in the queue such that the subs define the rules on how they get the data. The queue is like a pool, does not categorize the messages into categories. Broker applies the subscribers’ rules on every msg. (content-based pub-sub model)
Model 3 → Kafka combined with KSQL: Hybrid version combining 1 and 2. (topic+content)
Ranking
Scalability: Best: Topic based, worst: queue based
Therefore, topic based model is the most convenient
Pub-sub model example
Apache Kafka
Advantages
High throughput: can handle millions of messages per second (LinkedIn 3.2Million msgs/sec)
High performance: uses in-memory writes and reads
Fault tolerant: Kafka is highly available and resilient to node failures and supports automatic recovery.
Elastically scalable, low operational overhead, durable, highly available
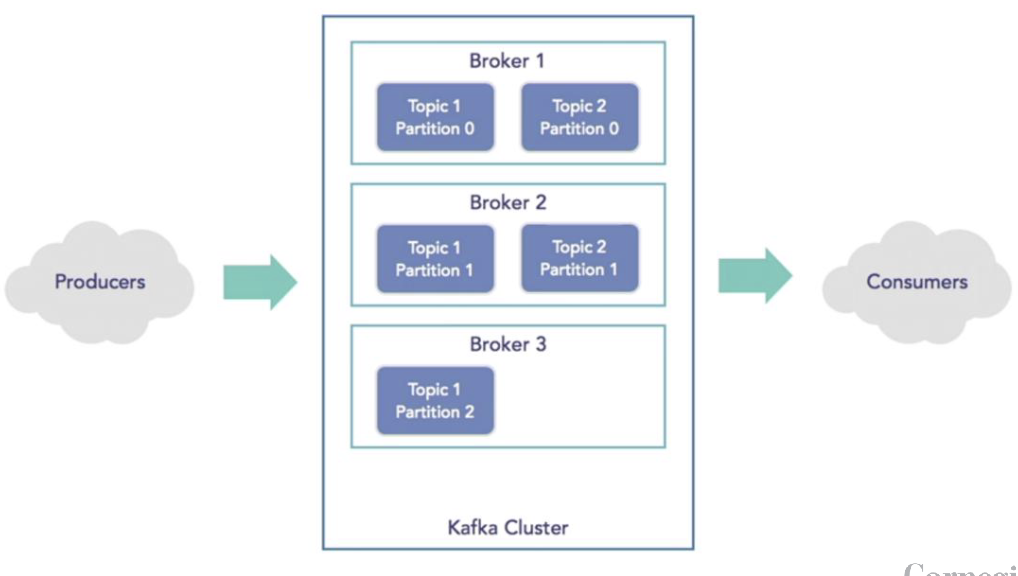
Structure
Topics
Is a particular stream of data. Is the unit of parallelism in Apache Kafka.
You can have as many topics as you want
Identified by a name, divided into partitions
Partitions
To enhance scalability, we create partitions to the topics, each piece sits in independent space in the memory, and we can have as many partitions as we want for the same topic. But if the producer write messages into the same partition, we cannot guarantee the consumer to do the changes in the same order. So within the same partition, the messages are ordered through offset, but there is no order across partitions.
Each partition is ordered
Each message within a partition has an offset (an incremental, unique id)
To enable fault tolerance, we can get duplication of partition in indifferent brokers.
Each partition lives in an individual machine, called broker
Brokers
A Kafka cluster is made up of multiple brokers (servers)
Each broker is identified by an id (integer)
Each broker contains one or more partitions for one or more topics
After connecting to any broker, you will be connected to the entire cluster (If i have the addr of B1, I also got the addr of B2, B3, etc)
Producers
Producers publish/write data to topics (which are made of partitions) while does not know which partition it will write to. Broker will deal with that
Producers automatically know to which broker and partition they should write to
In case of Broker failure, producers will automatically recover the failed broker
Producers choose whether to receive an acknowledgment of a successful write (ack), and whether to send a key with the message. If two msgs are sent with the same key, we can guarantee they will be sent to the same partition, even though we don’t know which partition it is.
Consumers
Consumers read data from a topic (identified by a topic name)
Consumers know which broker to read from.
In case of Broker failures, consumers know how to recover the failed broker.
Data are read in order within each partition.
Consumer group: a set of consumers that share and load-balance the partitions of a topic, ensuring each partition is consumed by exactly one consumer in the group. Different groups consume independently, so each group receives a full copy of the topic’s messages.
Why group.id helps:
Parallelism: all consumers with the same group.id share the work of reading a topic, Each partition’s messages go to exactly one consumer in the group. Add more consumers to the group → partitions get redistributed → higher parallelism (up to number of partitions).
At-least-once delivery/fault tolerance: each consumer in the group keeps track of its read offsets. If a consumer crashes and restarts, it resumes reading from its last committed offset, ensuring no messages are missed.
Multiple independent applications: Different groups consume independently, so each group receives a full copy of the topic’s messages.
Zookeeper
Connects Partition and OS adding ports or system calls to OS such that partition can interact with the memory, to write and read the memory.
Manages and coordinates the brokers (keeps a list of them)
Helps in performing election for partitions
Sends notification to Kafka in case of changes (new broker added, broker failure, new topic, etc)
An important component of Kafka.
Causes the hardness of deploying Kafka as it is on the top of OS to build the communication, and enable the Kafka to run smoothly and directly in different platforms and OS.
Parallelism
A topic partition is the unit of parallelism in Kafka. Each partition can be hosted on a different broker (server) in the Kafka cluster.
Producers and brokers:
Writes to different partitions can be done in parallel.
Parallelism frees up hardware resources for operations like compression.
Consumers:
You can have up to one consumer instance per partition within a consumer group.
Any additional consumers beyond the number of partitions will remain idle.
Kafka cluster: more partitions in a Kafka cluster lead to higher system throughput.
Scalable partitioning: you can increase or decrease the number of partitions in a topic as your data volume and throughput requirements change over time.
Keyed messages caution: exercise caution when messages are produced with keys, as they are deterministically assigned to partitions.
Consistent routing: kafka ensures that messages with identical keys are consistently routed to the same partition, preserving the integrity of order-dependent applications.
Digression 2: Microservices
Divide a computation into small, mostly stateless components that can be: easily replicated for scale, communicate with simple protocols, computation is as a swarm of communicating workers.
Stateless: each component does not store any state between requests. Each request is independent.
In cloud, it typically runs as containers using a service deployment and management service on systems like: Amazon Elastic Container service, GKE, DCOS from Berkeley/Mesosphere, Docker Swarm
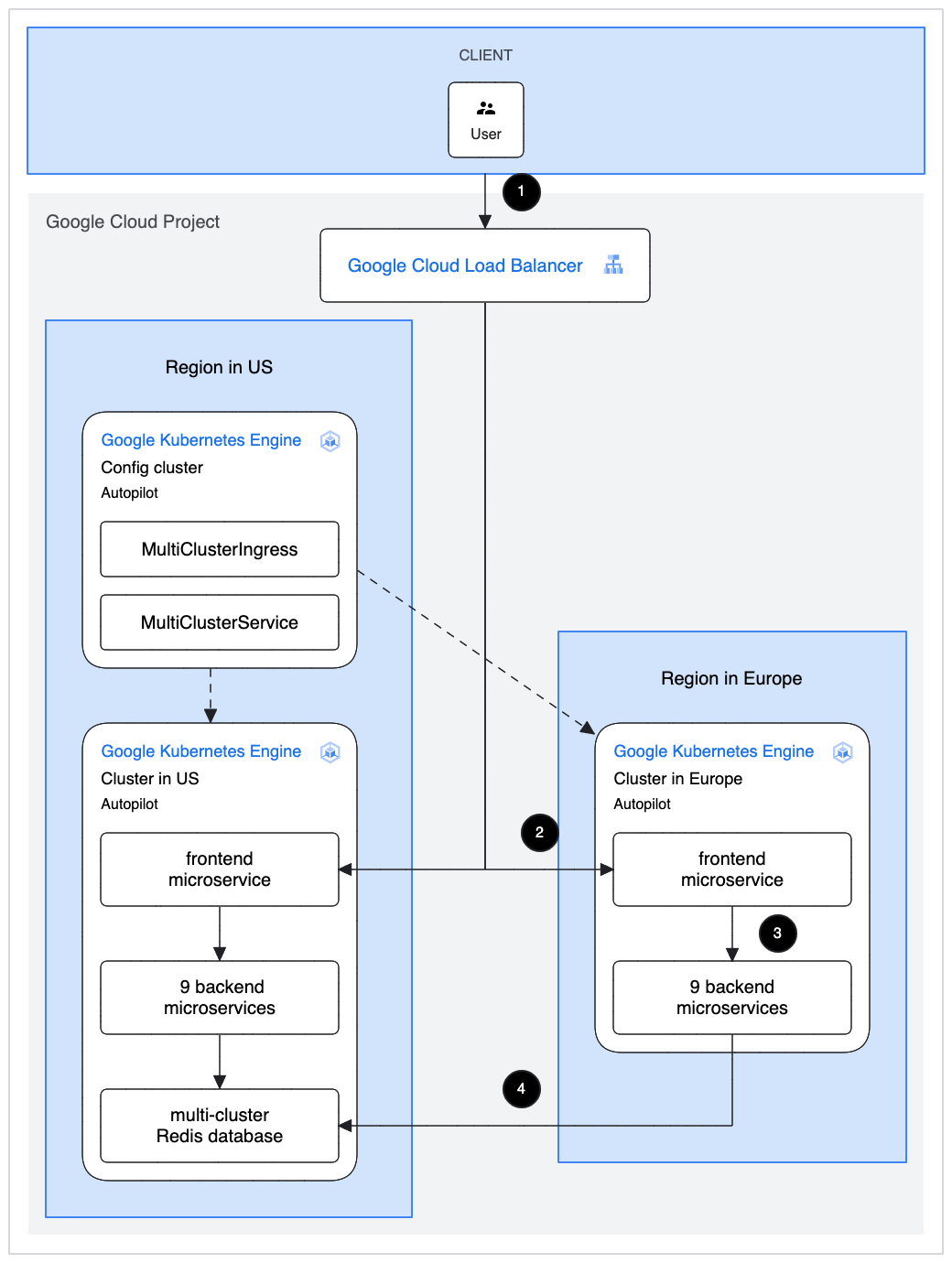
Cymbal Shops: This solution deploys a demo application called Cymbal Shops (also known as Online Boutique). Cymbal Shops consists of about 10 microservices. The source code of each microservice is available in a separate, open source GitHub repository.
3 Google Kubernetes Engine (GKE) clusters: This solution provisions a total of 3 GKE cluster — 2 clusters in the US, and 1 cluster in Europe. One of the US clusters will be used for configuring multi-cluster ingress, while the other 2 clusters will host the microservices of the Cymbal Shops application (including the frontend microservice).
Static external IP address: The Cymbal Shops application will be pubicly acessible via an IP address, reserved and output (into your command line interface) by the Terraform. The IP address may take about 5 minutes to actually serve the frontend since multi-cluster ingress takes a few minutes to warm up.
Single Redis cart database: The items in users’ carts are managed in a single Redis databases, only deployed to a US cluster — for data consistency.
Digression 3: REST
provide an interface for distributed hypermedia systems, created by Roy Fielding in 2000
The key abstraction of information in REST is a resource
Identified by a resource identifier, i.e. URI
Resources can be retrieved or transformed to another state by aset of methods:
GET/PUT(update) /POST (add)/DELETE/PATCH (Update a lot of resources)
The clients and servers exchange representations of resources by using a standardized interface and protocol typically HTTP
Kafka + Mircroservices
Code Example
Producer example (Python):
import socket
from confluent_kafka import Producer
# Kafka settingsBROKER ='localhost:9092'# Change this to your Kafka broker addressTOPIC ='simple_topic'# Replace with your Kafka topic# Function to create a Kafka Producerdefcreate_kafka_producer(broker):
conf = {
'bootstrap.servers': broker,
'client.id': socket.gethostname()
}
producer = Producer(conf)
return producer
defpublish_simple_message():
producer = create_kafka_producer(BROKER)
producer.produce(TOPIC, key="message", value="Yes, it's me!")
producer.flush()
if __name__ =="__main__":
publish_simple_message()
Consumer example - creation code:
# Creation codeimport socket
from confluent_kafka import Producer
# Kafka settingsBROKER ='localhost:9092'# Change this to your Kafka broker addressTOPIC ='simple_topic'# Replace with your Kafka topic# Function to create a Kafka Producerdefcreate_kafka_producer(broker):
conf = {
'bootstrap.servers': broker,
'client.id': socket.gethostname()
}
producer = Producer(conf)
return producer
defpublish_simple_message():
producer = create_kafka_producer(BROKER)
producer.produce(TOPIC, key="message", value="Yes, it's me!")
producer.flush()
if __name__ =="__main__":
publish_simple_message()
Consumer example: poll loop
# Display data from Kafkadefdisplay_kafka_data():
consumer = create_kafka_consumer(BROKER, GROUP_ID, TOPIC)
whileTrue:
msg = consumer.poll(timeout=1.0)
if msg isNone:
continueif msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
continueelse:
print(msg.error())
break key = msg.key().decode('utf-8')
value = msg.value().decode('utf-8')
# Display message with an icon print("New Message Alert!!")
print(f"Key: {key} and Value: {value}")
consumer.close()
if __name__ =="__main__":
display_kafka_data()
Confluent Kafka
Since Handling Kafka requires managing low-level, complex data infrastructure, we have Confluent Kafka. It is built on top of Apache Kafka to offer complete, fully managed, cloud-native data streaming that’s available wherever your data and applications reside.